- Infrastruktur
Hochverfügbarkeit beginnt nicht beim dritten Node – sondern bei der Planung
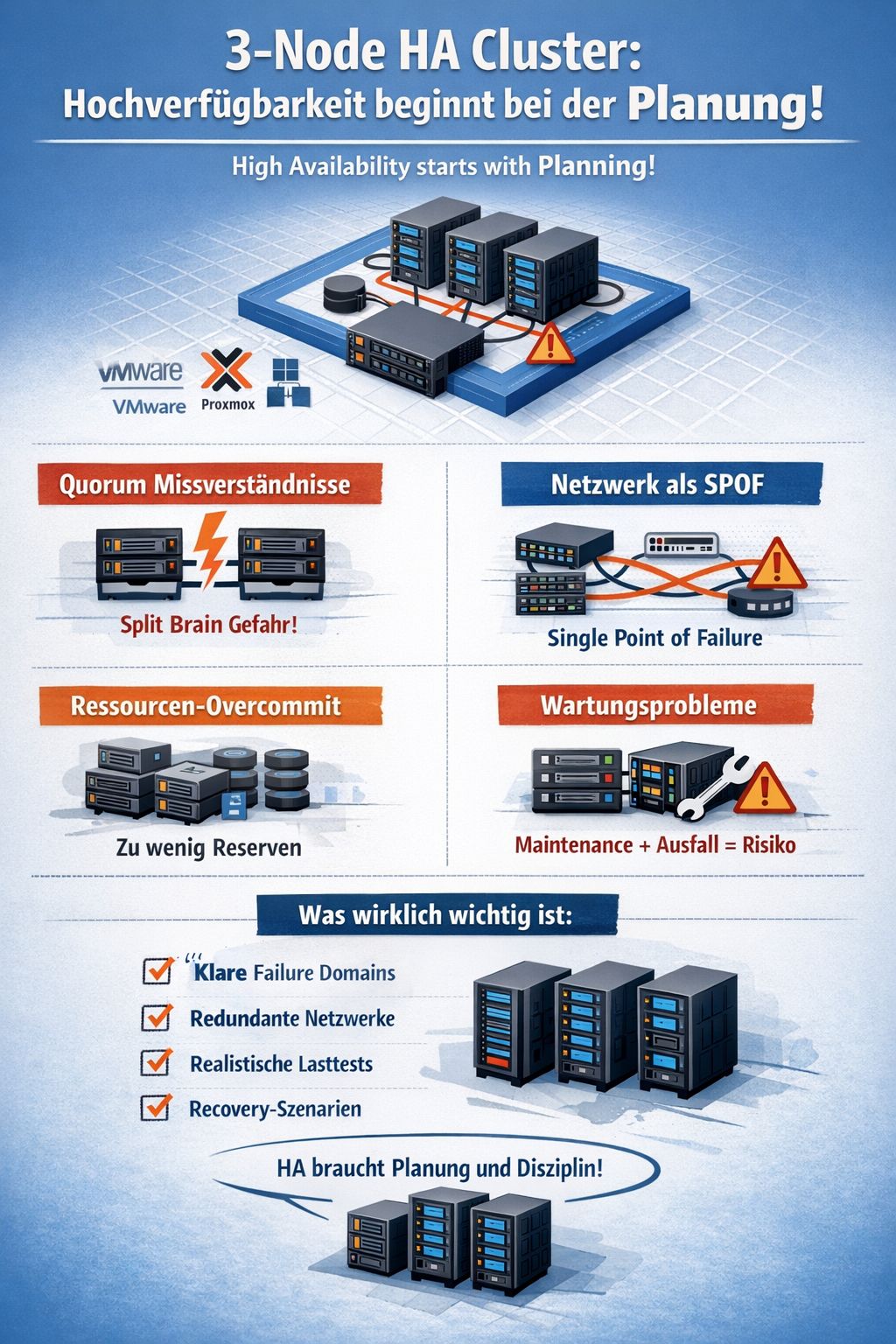
3-Node HA-Cluster gelten als Standardlösung für KMU. In der Praxis scheitern viele Setups aber nicht an der Hardware – sondern an architektonischen Schwächen.

Thomas Luginger
Hochverfügbarkeit beginnt nicht beim dritten Node – sondern bei der Planung.
Die Einrichtung von 3-Node-HA-Clustern gilt in kleinen und mittleren Umgebungen oft als Standardlösung: Drei Server, Shared Storage oder HCI, ein Witness – fertig. In der Praxis scheitern aber viele Setups nicht an der Hardware, sondern an architektonischen Schwächen.
Nach 27 Jahren in der IT erkenne ich immer wieder vier wiederkehrende Muster:
1. Quorum falsch verstanden Ein 3-Node-Cluster toleriert genau einen Ausfall. Wird das Quorum in VMware/Broadcom vSphere, Microsoft Failover Cluster oder Proxmox VE nicht korrekt implementiert, drohen Split-Brain-Szenarien.
2. Netzwerk als Single Point of Failure Redundante Nodes nützen wenig, wenn Heartbeat und Storage über dieselben Switches laufen, VLANs keine physische Trennung haben oder Latenz unter Last nicht getestet wurde.
3. Ressourcen-Overcommitment Die Kapazitätsplanung muss sicherstellen, dass alle Workloads auch im N-1-Betrieb dauerhaft stabil laufen – nicht nur kurzzeitig.
4. Maintenance Windows nicht berücksichtigt Ein Node im Wartungsmodus plus ein ungeplanter Ausfall ergibt ein Produktionsproblem.
Fazit: Erfolgreiche Hochverfügbarkeit erfordert architektonische Disziplin – mit klaren Failure Domains, getrennten Netzwerkpfaden, realistischen Lasttests und dokumentierten Recovery-Prozeduren.